
Determining how closely a customer’s search query matches the products offered presents a significant challenge for modern e-commerce platforms, and is becoming increasingly crucial as artificial intelligence drives online shopping experiences. Pengkun Jiao, Yiming Jin, and Jianhui Yang, along with their colleagues, address this problem by introducing a new framework, TaoSR-SHE, designed to improve search relevance for Taobao. This research overcomes limitations in existing training methods, which often struggle with complex or unusual searches and lack detailed guidance for accurate reasoning. TaoSR-SHE employs a novel reinforcement learning algorithm that learns from both automatically generated feedback and human verification, focusing on correcting errors at each step of the reasoning process, and ultimately delivers improved accuracy, interpretability and robustness in large-scale e-commerce search.
Reasoning Model Refinement via Reinforcement Learning
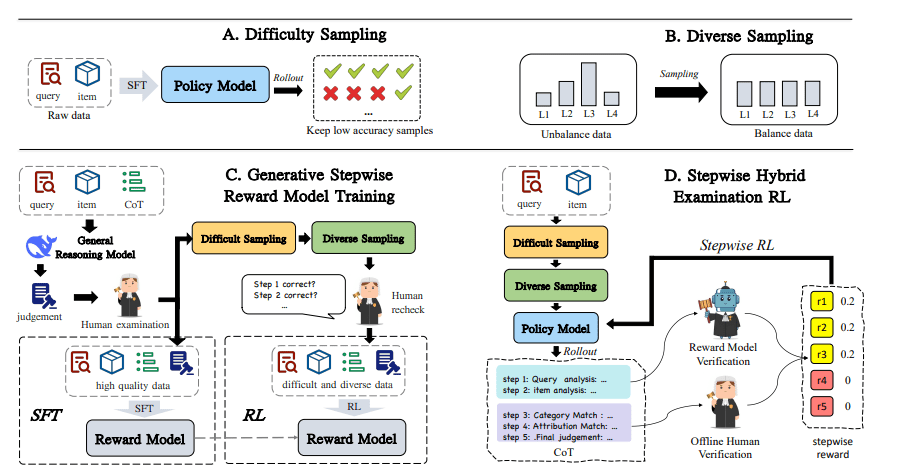
The research focuses on a General Reasoning Model, employing a Chain of Thought approach coupled with a Reward Model refined through Reinforcement Learning with diverse sampling. Human examination plays a crucial role in evaluating both Supervised Fine-Tuning and Reinforcement Learning stages, utilising high quality and varied data to enhance model performance. A Generative Stepwise Reward Model is trained, with its outputs subject to human re-evaluation at each step to assess the correctness of reasoning. This iterative process forms the basis of a Stepwise Hybrid Examination approach within the Reinforcement Learning framework, beginning with query and item analysis to refine the model’s reasoning capabilities.
Stepwise Hybrid Examination for Search Relevance
This research details a new framework, TaoSR-SHE, designed to improve the relevance of search results in e-commerce using Reinforcement Learning from Human Feedback. The core innovation is a Stepwise Hybrid Examination approach within the Reinforcement Learning pipeline, addressing limitations in traditional methods by providing granular feedback and understanding model decisions. The system provides rewards at each step of the search result generation process, allowing for more targeted learning through a combination of automated evaluation and human feedback. The paper emphasizes the use of a Generative Reward Model, which not only provides a score but also explains its reasoning, crucial for debugging and improvement. Experiments demonstrate that this model consistently outperforms baseline models in online evaluations, allowing for granular learning and better alignment with human preferences. The generative aspect provides valuable insights into the system’s decision-making process, facilitating refinement and resulting in accurate and consistent judgments.
Stepwise Reward Optimisation Improves Search Relevance
The research team has developed a new framework, TaoSR-SHE, to significantly improve the accuracy and interpretability of search relevance in e-commerce systems. Addressing limitations in existing training methods, they introduced Stepwise Reward Policy Optimization, leveraging a high-quality generative model and human verification to prioritise learning from critical steps in the reasoning process. Experiments demonstrate that this approach effectively estimates step-level advantages, a crucial improvement over existing methods. The team developed a Stepwise Hybrid Reward scheme, assigning rewards based on the specific step in a five-step reasoning process: query interpretation, item interpretation, category relevance, attribute relevance, and final ranking. For the initial two steps, the generative reward model provides feedback, while steps three and four utilise pre-computed ground truth data for increased accuracy. Diversified data filtering encourages exploration of varied reasoning paths, and a multi-stage curriculum learning strategy progressively builds the system’s capabilities, resulting in demonstrably improved reasoning quality and relevance-prediction accuracy.
Stepwise Rewards Improve E-commerce Search Relevance
The research team has developed a new framework, TaoSR-SHE, to improve the accuracy and interpretability of search relevance systems in e-commerce. Addressing limitations in existing training methods, they introduced Stepwise Reward Policy Optimization, leveraging a high-quality generative model and human verification to provide rewards at each step of the reasoning process, prioritising learning from critical points where the system succeeds or fails. Experiments on real-world e-commerce search data demonstrate that TaoSR-SHE outperforms existing methods in both reasoning quality and relevance prediction, while also improving the system’s ability to explain its decisions. To further enhance performance, the team incorporated techniques to encourage exploration of diverse reasoning paths and a curriculum learning approach that progressively builds the system’s capabilities. The authors acknowledge that obtaining extensive human annotations can be costly, and that a reward-only approach can still deliver competitive results, suggesting future work could explore methods for reducing reliance on human input and further refining the curriculum learning process.
👉 More information
🗞 TaoSR-SHE: Stepwise Hybrid Examination Reinforcement Learning Framework for E-commerce Search Relevance
🧠 ArXiv: https://arxiv.org/abs/2510.07972







